
Author:
- Name: J. David Lowe
Location: US - United States of America (United States)
To build:
makeBugs and (Mis)features:
The current status of this entry is:
STATUS: missing or dead link or links - please provide it or them
STATUS: INABIAF - please DO NOT fix
For more detailed information see 2011/dlowe in bugs.html.
To use:
./dlowe -<n_iterations> corpus1/ [...] corpus0/ < start.net > trained.netNOTE: In the above command, the directory args MUST end in a /.
Then to use trained.net:
./dlowe file [file ...] < trained.netTry:
Try these pre-trained networks:
./try.shNOTE: The dlowe-aux-data directory, which try.sh refers to, was created by:
tar -jxf dlowe-aux-data.tar.bz2Judges’ remarks:
This entry is a ghoulish example of a brain (dead?) neural network classifier. It comes with a set of corpora for you to try.
ioccc-winlose-trained.net
You can create your own trained networks. For example, we trained a network on the C code of entries that were supplied to the 20Th IOCCC.
The ioccc-winlose-trained.net was trained using the
earlystop.pl tool:
rm -f ioccc-winlose-trained.net
./earlystop.pl ioccc-winlose-trained.net ioccc_won_training/ ioccc_lost_training/ ioccc_won_test/ ioccc_lost_test/where:
ioccc_won_training/1/2 of C code of the 20th IOCCC entries (except for dlowe.c from 2011) plus 1/2 of the C code winning entries from prior IOCCC contestsioccc_won_test/1/2 of C code of the 20th IOCCC entries (except for dlowe.c from 2011) plus 1/2 of the C code winning entries from prior IOCCC contestsioccc_lost_training/1/2 of C code from entries that that did not winioccc_lost_test/1/2 of C code from entries that that did not win
NOTE: The above directories were not shipped and everything from the entries
that did not win were flushed to /dev/null.
The earlystop.pl tool wrote:
training 1 to 1001...
training 1001 to 2001...
prior error = 56.746974766043; current error = 58.095691135305The resulting ioccc-winlose-trained.net file was included in the
dlowe-aux-data.tar.bz2 tarball.
The dlowe.c was explicitly excluded from this trailing set, so this test is interesting:
./dlowe dlowe.c < dlowe-aux-data/ioccc-winlose-trained.netNOTE: this is done in try.sh.
The match of dlowe.c to the lose/win trailed network was:
dlowe.c 0.125108NOTE: The non-artificially intelligent decisions of the IOCCC judges include random quirks and their non-linear judgment calls not found in the ioccc trained network. Just because C code is or isn’t scored highly by this network does not mean it will win or lose a future IOCCC. On the other hand … it just might!
other data sets to try
While we cannot supply you with the losing IOCCC source code, the author did supply a number data sets on which to test:
We created the english-trained.net as follows:
./dlowe -8000 dlowe-aux-data/english-1/ dlowe-aux-data/english-0/ < /dev/null > dlowe-aux-data/english-trained.netdlowe-aux-data/english-0/ Non-English (French) text
dlowe-aux-data/english-1/ English (non-French) text
We created the png-trained.net as follows:
./dlowe -8000 png-1/ png-0/ < /dev/null > dlowe-aux-data/png-trained.netdlowe-aux-data/png-0/ Non-png (gif) images
dlowe-aux-data/png-1/ png (non-gif) images
We created the xor-trained.net as follows:
./dlowe -8000 dlowe-aux-data/xor-1/ dlowe-aux-data/xor-0/ < /dev/null > dlowe-aux-data/xor-trained.netdlowe-aux-data/xor-0 Data that XORs to 0
dlowe-aux-data/xor-1/ Data that XORs to 1
NOTE: The directory args must end in a / for them to work.
Author’s remarks:
Synopsis
This is an artificially intelligent judging tool to help the IOCCC judges. Here’s to shorter, more frequent contests!
Description
This is a multilayer perceptron, a feedforward artificial neural network, which can be trained, using on-line backpropagation, to classify input files.
It has a fixed topology of 2^16 input neurons, 6 hidden neurons and 1 output
neuron.
The neurons’ activation function is the logistic function 1 / (1 + e ^ -x).
Classifying
./dlowe file [file ...] < trained.netTo classify files, one specifies a trained network (on stdin) and one or more
files to classify. The program will output one line per successfully-classified
file to stderr, with the filename and the classification: a number between 0
and 1.
The interpretation of the classification number depends on how the network was trained, but it’s geared toward interpretation as a probability or a confidence.
Training
./dlowe -<n_iterations> corpus1/ [...] corpus0/ < start.net > end.netNOTE: The directory args must end in a / for them to work.
To train a network, one specifies a starting network (on stdin), two or more
corpora (directories containing training data), and the number of training
iterations to run. The program will write some progress data to stderr and,
when it’s done, will serialize the updated network to stdout.
If no input network is given, a random new network will be generated as a
starting point (i.e. provide an empty stdin).
The first corpus will be assigned a target value of 1. The last will be
assigned a target value of 0. Intervening directories (if any) will be assigned
intermediate target values.
The learning rate is hard-coded as 0.3. No momentum factor is used.
png corpora
The dlowe-aux-data/png-1 corpus was obtained by manually scraping the first results from an
https://images.google.com search for “obfuscate
filetype:png”.
The dlowe-aux-data/png-0 corpus was obtained by manually scraping the first results from an
https://images.google.com search for “obfuscate
filetype:gif”.
Results:
- Using these corpora as a training set;
- Using several hundred random
*.gifand*.pngfiles from my home computer as a test set; - Using the included earlystop.pl script, which stopped after 67000 iterations.
- Interpreting output of
> 0.5as “probably a.png” and< 0.5as “probably a.gif”
produced a network with about 87% accuracy
English corpora
The english-1 corpus was obtained by manually scraping the first results from a https://www.google.com/webhp?lr=lang_en search for “paris filetype:txt”.
The english-0 corpus was obtained by manually scraping the first results from a https://www.google.com/webhp?lr=lang_fr search for “paris filetype:txt”.
Results:
- Using these corpora as a training set;
- Using several dozen additional text files (obtained by the same methods) as a test set;
- Using the included earlystop.pl script, which stopped after 10000 iterations;
- Interpreting output of
> 0.5as “probably English” and< 0.5as “probably French”
produced a network with 100% accuracy.
xor corpora
The xor-1 corpus consists of two files containing 01
and 10 respectively.
The xor-0 corpus consists of two files containing 00
and 11 respectively.
Results:
Using these corpora as a training set takes about 8000 iterations to learn xor
to within a tolerance of <0.01.
Limitations
The program can’t tell you anything meaningful about files with less than two bytes in them (I’m looking at you, smr.c!)
You must include the trailing directory separator on training directories (this allows the program to be portable without wasting precious bytes on figuring out how to concatenate directory and file names…).
Serialized network files are only portable between systems with the same floating-point representation and endianness.
Making sure not to overfit the network to the training data is a bit of a black art. I have enclosed earlystop.pl, a wrapper script that implements a simple ‘early stopping’ algorithm; other techniques are possible.
Bad input (e.g. nonexistent files, non-numeric number of iterations, etc.) tends to result in empty output.
Given exactly one corpus, the program will crash or produce garbage.
Leaks memory and file descriptors while processing files.
Will crash and die horribly if it runs out of memory.
The Microsoft C compiler doesn’t provide a dirent API, so to get this working
on a Windows system you’ll need cygwin+gcc (tested) or a dirent compatibility
library (untested, but they do exist).
Backpropagation doesn’t always converge: if you play with this long enough, you’ll eventually have a training session that completely fails to converge.
Obfuscation
- Zombies! (Since neural networks are modeled after BRAINS, ya know? And corpus sounds a lot like corpse. And I have 4- and 7-year-old kids ;) )
- Neural networks are interesting, and while the math isn’t terribly difficult, their behavior is difficult to fully understand.
- Had some extra space in one of the major data structures, and it seemed a shame to waste it.
- Similarly, I think three file pointers ought to be enough for anyone.
- Lots of magic numbers expressed in various ways.
- Random abuse of random C trivia.
- Some textual changes were made to maximize the classification of this program by a network trained to recognize IOCCC entries ;)
… but mostly zombies!
Inventory for 2011/dlowe
Primary files
- dlowe.c - entry source code
- Makefile - entry Makefile
- dlowe.orig.c - original source code
- earlystop.pl - wrapper script to stop training early
- try.sh - script to try entry
- dlowe-aux-data/png-0/5756029-DMZ-overview-B.gif - Non-png gif images
- dlowe-aux-data/png-0/M2.gif - Non-png gif images
- dlowe-aux-data/png-0/Obfuscate.gif - Non-png gif images
- dlowe-aux-data/png-0/figure_49.gif - Non-png gif images
- dlowe-aux-data/png-0/klockhuset.gif - Non-png gif images
- dlowe-aux-data/png-0/obfuscate_1.gif - Non-png gif images
- dlowe-aux-data/png-0/podcastimage_150215.gif - Non-png gif images
- dlowe-aux-data/png-0/prjman1.gif - Non-png gif images
- dlowe-aux-data/png-0/proguard_obfuscate.gif - Non-png gif images
- dlowe-aux-data/png-0/scripts_encryptor_screnc-31918.gif - Non-png gif images
- dlowe-aux-data/png-0/visual_panel.gif - Non-png gif images
- dlowe-aux-data/english-0/040604.txt - training text for neural networks
- dlowe-aux-data/english-0/2001-2002.txt - training text for neural networks
- dlowe-aux-data/english-0/CFP_TSI_Graphes_appel.txt - training text for neural networks
- dlowe-aux-data/english-0/CIR_APE_08_doc.txt - training text for neural networks
- dlowe-aux-data/english-0/admin_fr.txt - training text for neural networks
- dlowe-aux-data/english-0/agenda.txt - training text for neural networks
- dlowe-aux-data/english-0/paris2.txt - training text for neural networks
- dlowe-aux-data/english-0/paris.txt - training text for neural networks
- dlowe-aux-data/english-0/structures3D-Paris.txt - training text for neural networks
- dlowe-aux-data/english-1/02-chronology.txt - training text for neural networks
- dlowe-aux-data/english-1/36C215.txt - training text for neural networks
- dlowe-aux-data/english-1/Wireless_Days_2011_CFP.txt - training text for neural networks
- dlowe-aux-data/english-1/cpb.txt - training text for neural networks
- dlowe-aux-data/english-1/get-there.txt - training text for neural networks
- dlowe-aux-data/english-1/pa_fv010.txt - training text for neural networks
- dlowe-aux-data/english-1/the_poor_people_of_paris.txt - training text for neural networks
- dlowe-aux-data/english-1/utmost.txt - training text for neural networks
- dlowe-aux-data/english-1/walljpar.txt - training text for neural networks
- dlowe-aux-data/xor-0/00 - training digits for neural networks
- dlowe-aux-data/xor-0/11 - training digits for neural networks
- dlowe-aux-data/xor-1/01 - training digits for neural networks
- dlowe-aux-data/xor-1/10 - training digits for neural networks
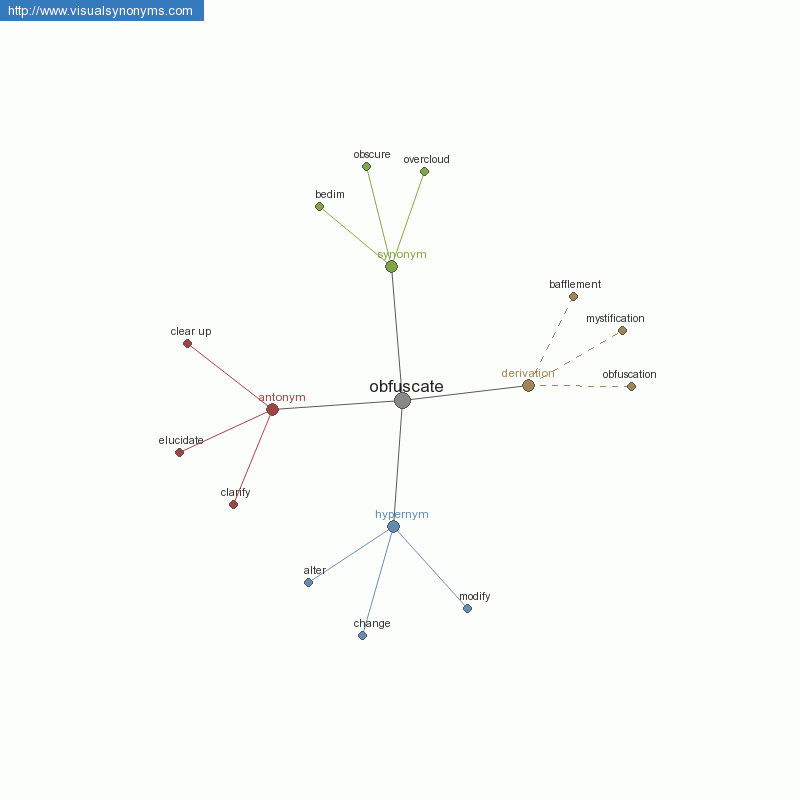
- dlowe-aux-data/png-1/JavaScript-obfuscation-code.png - training image for neural networks
- dlowe-aux-data/png-1/control_flow_obfuscation_before.png - training image for neural networks
- dlowe-aux-data/png-1/deceive-inveigle-obfuscate-t-shirts.png - training image for neural networks
- dlowe-aux-data/png-1/help_obfuscation1.png - training image for neural networks
- dlowe-aux-data/png-1/image_thumb.png - training image for neural networks
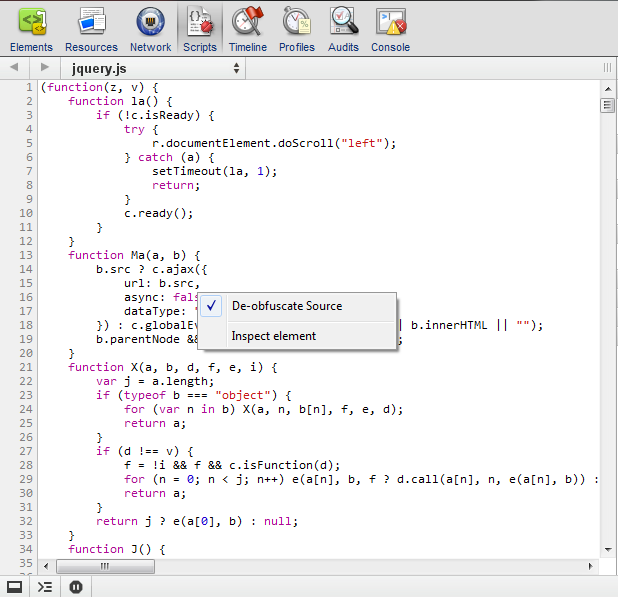
- dlowe-aux-data/png-1/jquery_after_deobfuscation.png - training image for neural networks
- dlowe-aux-data/png-1/obfuscate4e.png - training image for neural networks
- dlowe-aux-data/png-1/obfuscation-decoder.png - training image for neural networks
- dlowe-aux-data/png-1/obfuscation_methods.png - training image for neural networks
Secondary files
- 2011_dlowe.tar.bz2 - download entry tarball
- README.md - markdown source for this web page
- dlowe-aux-data/english-trained.net - trained neural network for English text
- dlowe-aux-data/ioccc-winlose-trained.net - trained neural network for C code from 20th IOCCC
- dlowe-aux-data/png-trained.net - trained neural network for png-0 and png-1 images
- dlowe-aux-data.tar.bz2 - tarball of IOCCC win lose trained network
- dlowe-aux-data/xor-trained.net - trained neural network for xor-0 and xor-1 data
- .entry.json - entry summary and manifest in JSON
- .gitignore - list of files that should not be committed under git
- .path - directory path from top level directory
- index.html - this web page



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}